









服務熱線
0755-83044319

發布時間:2025-02-27作者來源:薩科微瀏覽:966
人工智能大模型的架構可以從基礎結構、核心組件和演進趨勢三個層面進行解析:
一、基礎架構框架
1. Transformer核心:采用自注意力機制構建堆疊層,典型結構包含12-128層(如GPT-3有96層),每層含多頭注意力模塊和前饋網絡
2. 參數分布:千億級參數分布在注意力頭(占比約30%)、前饋網絡(約60%)及嵌入層(約10%)
3. 并行計算架構:使用張量/流水線/數據并行策略,如Megatron-LM采用3D并行訓練框架
二、關鍵組件解析
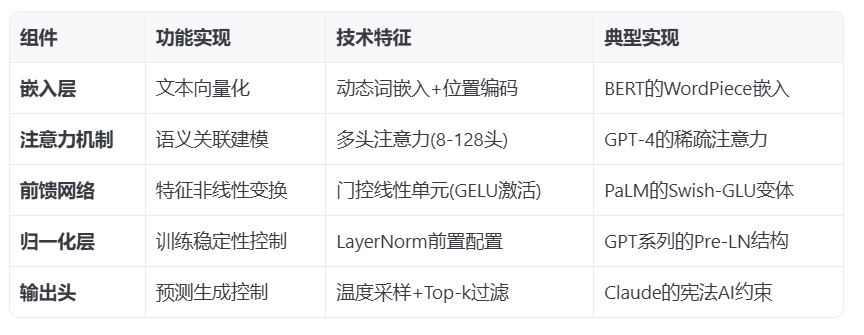
三、訓練流程架構 1. 預訓練階段:
- 數據吞吐:日均處理TB級文本,使用課程學習策略逐步增加難度 - 優化器:AdamW+混合精度訓練,學習率余弦衰減 - 硬件配置:數千塊A100/H100 GPU集群,顯存優化技術如ZeRO-3 2. 微調架構:
- 參數高效方法:LoRA(低秩適配)僅更新0.1%參數 - 指令微調:通過人類反饋強化學習(RLHF)對齊模型行為 四、前沿架構演進 1. 多模態融合:如Flamingo模型的感知-語言交叉注意力門 2. 模塊化設計:Mixture-of-Experts架構(如GPT-4推測使用8-16個專家) 3. 記憶增強:外部知識庫檢索模塊(如RETRO模型的鄰域檢索機制) 4. 能量效率優化:稀疏激活架構(如Switch Transformer) 五、典型架構對比
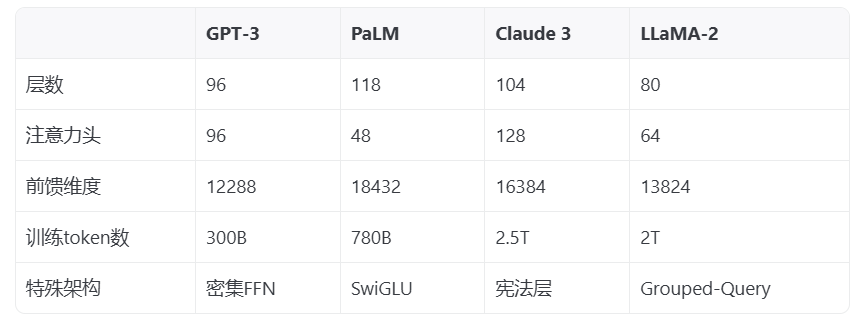
當前架構設計面臨三大挑戰:
① 注意力復雜度隨序列長度呈平方增長
② 超長上下文記憶保持(如10萬token以上)
③ 多模態信號對齊。
[敏感詞]解決方案包括滑動窗口注意力、狀態空間模型(SSM)以及跨模態對比學習。理解這些架構特征,有助于在具體應用中合理選擇模型,例如需要長文本理解時可選用采用環形注意力機制的模型,而多模態任務則應選擇具有交叉注意力門的設計。
免責聲明:本文采摘自“老虎說芯”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2025 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號
